Unalmas perceimben ezt a csodás protokollt implementáltam, mert protokollt implementálni jó. Szerencsére ezt nem az EU specifikálta mint az Openid4VP-t, így az egész egy vidám kis kódolási kalandnak indult.
Akit érdekel a draft specifikáció (mármint a sia, nem az openid), az itt elolvashatja.
Egyébként a SIA DC-09 használják, hogy riasztók a központi távfelügyeleti rendszerekkel (a szakmabelieknek ezt CSR-nek hívják, mint Central Station Receivers) kommunikálnak, és meglepő módon én is pont erre szerettem volna használni.
Miután a távfelügyeleti szolgáltatómnál 1 napot eltelefonálgattam, elmagyaráztam, hogy nem vagyok telepítő, és a riasztórendszeremnek nincs márkája – hacsak a jdk-t nem tekintjük riasztó márkának – meg azt, hogy a SIA DS-09 egy kommunikációs protokoll, és abban SIA-DCS és ADM-CID üzenetek is mehetnek, és mondják már meg mit szeretnének kapni, megállapodtunk. Nekem egy AJAX márkájú riasztóm van, és küldjek DC-09-be csomagolt SIA-DCS üzeneteket. Amikor már arról győzködtek, hogy 128 bites AES-hez 32 karakteres a titkosító kulcs, már meg sem lepődtem… (persze náluk is 16 karakter, de hex formátumban adták, ezért volt 32).
Találtam a neten pár projektet, amik sia csr-ként tudtak működni, volt bennük unittest, amikből már jónak tűnő üzeneteket lehetett lopni, és szerencsére a specifikációban is volt pár példa. Amikor úgy éreztem minden működik, és mindenre felkészültem, jöhetett az igazi teszt. Életre kelteni a virtuális riasztóm a távfelügyeletnél.
A teszt kiválóan sikerült:
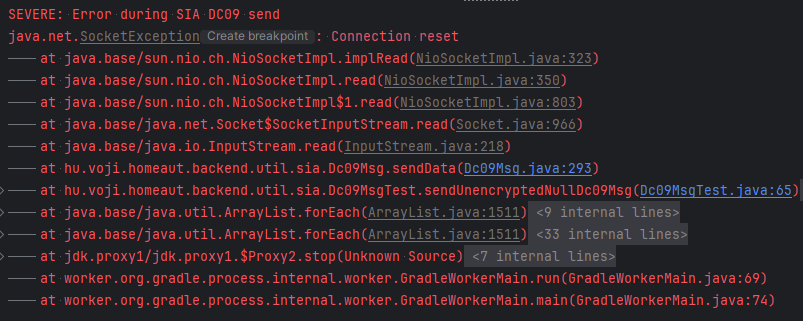
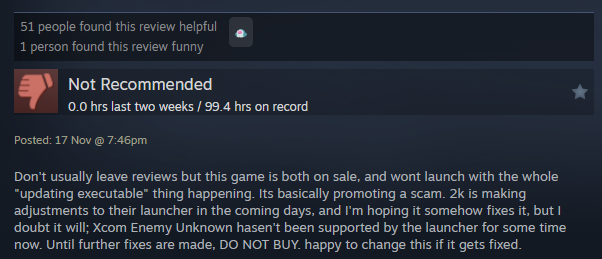
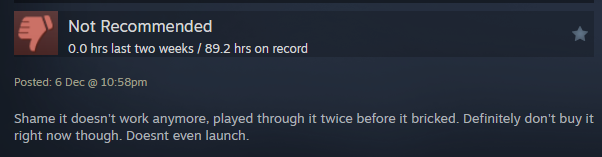
Kipróbáltam nagyjából mindent, minden általam talált riasztó központtal kommunikáltam, kivéve azzal amivel kellett volna, mert ott mindig így végződött a kommunikáció.
Gondoltam ránézek kicsit alaposabban, egész pontosan mi is történik itt. Hát nagyjából ez:
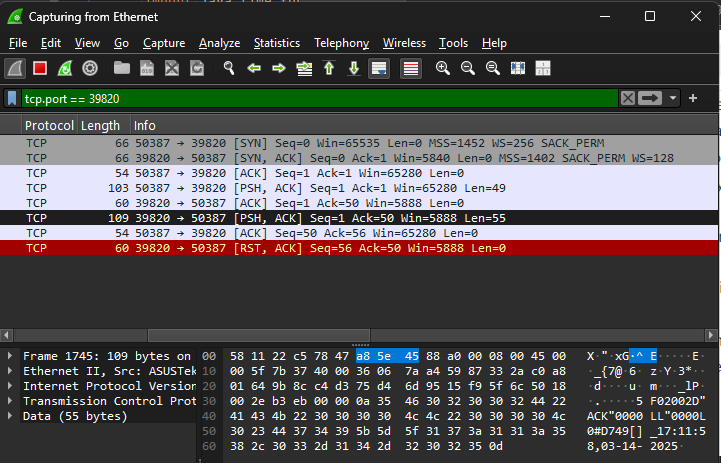
Bizony, jön vissza teljesen szabványos válasz üzenet, csak éppen nem kapom meg. És innen már az is látszik miért. Ha jön egy RST (FIN helyett) akkor a java dob egy connection reset szövegű SocketException-t. Szerencsére a buffer ilyenkor már fel van töltve, csak ki is kell olvasni azt, ami benne van.
public static String sendData(String host, int port, byte[] data, int timeout) {
byte[] buffer = new byte[2048];
StringBuilder responseBuilder = new StringBuilder();
int bytesRead = 0;
try (Socket socket = new Socket(host, port);
OutputStream outputStream = socket.getOutputStream();
InputStream inputStream = socket.getInputStream()) {
socket.setSoTimeout(timeout);
outputStream.write(data);
outputStream.flush();
// Read the response
while ((bytesRead = inputStream.read(buffer)) != -1) {
responseBuilder.append(new String(buffer, 0, bytesRead));
}
return responseBuilder.toString();
} catch (Exception e) {
//connection reset is not an error,
// because some CSR send RST after response
if (e instanceof SocketException
&& "Connection reset".equals(e.getMessage())) {
return responseBuilder.toString();
} else {
log.log(Level.SEVERE, "Error during SIA DC09 send", e);
}
}
return null;
}